
Insider Threat Protection: Strategies and Solutions to Defend Your Organization
Read Our Post

Everyone knows that today’s world revolves around data and being competitive requires enterprises to be data-driven. According to Accenture, 70% of the world’s most valuable corporations are data-driven, up from only 30% in 2008. Being data-driven requires enterprises to collect and store more and more data, and enterprises need to ensure that data is stored and used safely and appropriately. In other words, they need good data governance.
But for most enterprises, good data governance is really a broken promise. Or, as one financial services enterprise recently described to us:
"We have been up and down with data governance a few times in the past few years. There was a governance office. We “check-boxed” our way through and it was ultimately seen as more of a barrier than a benefit."
Enterprises cannot “check-box” their way through Data Governance. Check boxes imply manual processes. Check boxes also imply that their data really isn’t being governed.
Enterprises need to operationalize their Data Governance. They need DataGovOps.
Let’s peel this onion.
What is DataGovOps?
DataGovOps refers to the collaborative data management practice focused on improving the communication, integration and automation of context and policy among all Data Governance stakeholders in an organization, including Security, Compliance, Privacy, and Data Owners. DataGovOps automates the integration of security and compliance at every phase of the data lifecycle.
In order to fully appreciate what DataGovOps is and why it’s needed, it’s important to address:
However, to fully understand DataGovOps, we need to have a common understanding of what Data Governance is, who is responsible for Data Governance, how Data Governance functions typically operate, and the shortcomings of most Data Governance programs.
What is Data Governance?
According to Google Cloud, Data Governance is (with added emphasis):
…everything you do to ensure data is secure, private, accurate, available, and usable. It includes the actions people must take, the processes they must follow, and the technology that supports them throughout the data life cycle… Data governance means setting internal standards—data policies—that apply to how data is gathered, stored, processed, and disposed of. It governs who can access what kinds of data and what kinds of data are under governance.
Who’s Responsible for Data Governance?
Every enterprise has a Data Governance function. Whether or not it’s formally called “Data Governance” or has employees with “Data Governance” in their titles is another question.
In many large organizations, Data Governance is a distributed function or “program” across multiple teams, including:
Because Data Governance is a distributed function, relatively few professionals actually have Data Governance in their job title. A few searches on LinkedIn reveal:
So Data Governance is a cross-functional fabric that spans multiple teams and/or departments. Or, as we like to say, Data Governance takes a village -- it’s a shared responsibility that requires a significant amount of coordination and collaboration across multiple teams.
How Do Data Governance Programs Typically Operate?
Two words: divide and conquer.
To understand how a Data Governance program operates, we need to break down the above definition of data governance.
If Data Governance is everything you do to ensure data is available, secure, private, accurate, and usable, then Data Governance subsumes multiple functions. These functions include:
Visually, the Data Governance function might look like this. (Credit to the Storage Networking Industry Association for most of the section under Data Protection.)
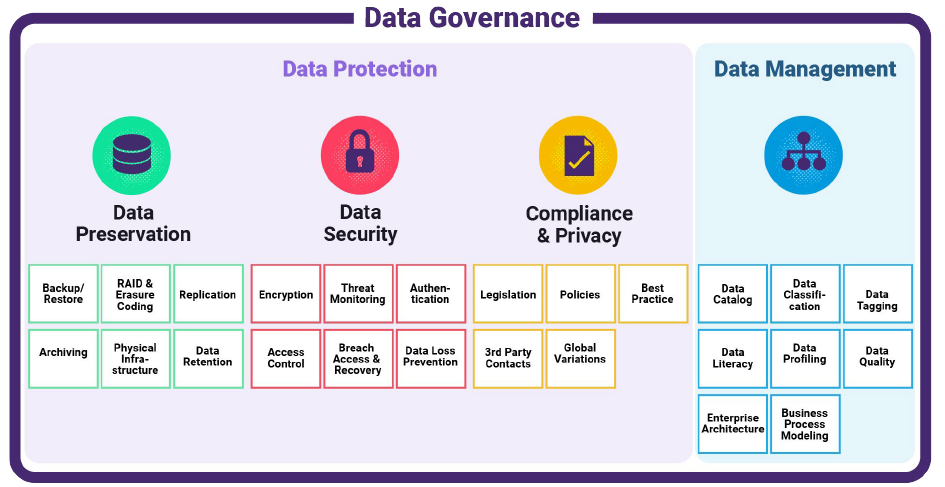 Figure 1: The Data Governance Function
Figure 1: The Data Governance Function
Given how the Data Governance function looks above, the reality of how Data Governance operates is this: the figure above ends up segmenting into separate teams, operating in silos, and occasionally interacting with each other via periodic sensitive data audits or access audits.
 Figure 2: Data Governance Functional Silos
Figure 2: Data Governance Functional Silos
The Problem with Data Governance and Functional Silos
There are 4 key problems when Data Governance is siloed by function.
Data suffers from a fundamental lack of governance between the periodic audits. This is what we call the broken promise of data governance.
In other words, state-of-the-art Data Governance currently looks like this:
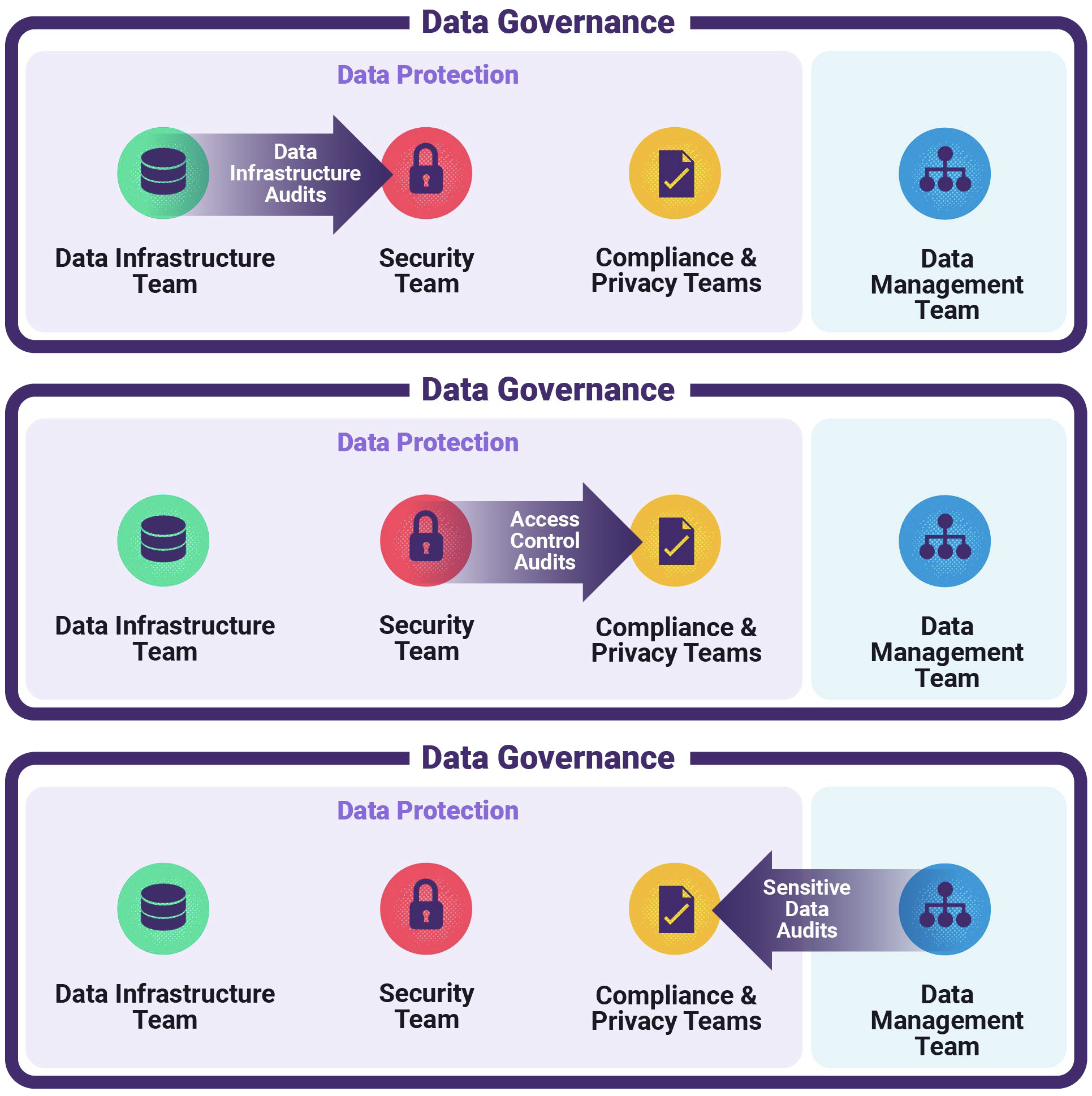 Figure 3: Data Governance via Cross-Functional Periodic Audits
Figure 3: Data Governance via Cross-Functional Periodic Audits
Ideally, Data Governance should behave/operate like this:
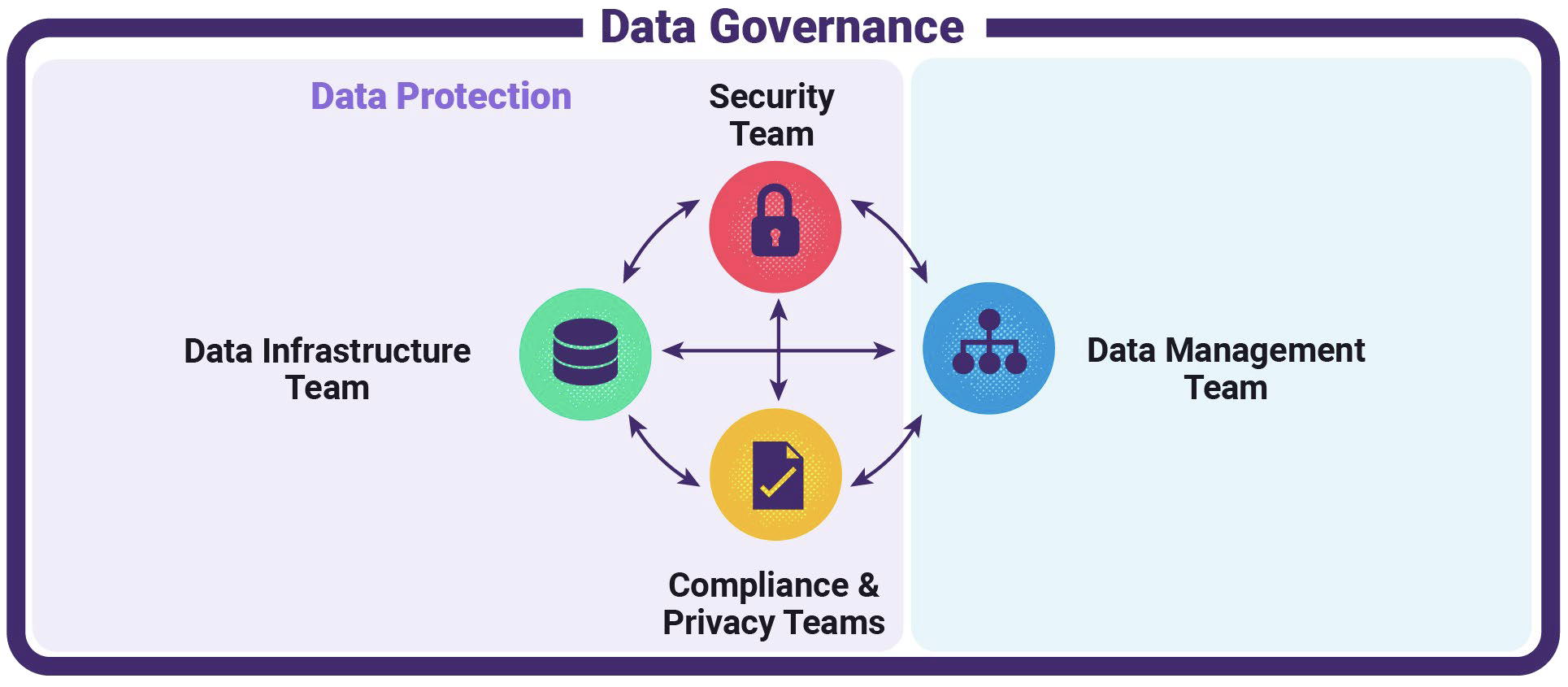 Figure 4: How Data Governance Should Ideally Operate
Figure 4: How Data Governance Should Ideally Operate
The Problem with Non-Continuous Data Governance
To illustrate the problem with non-continuous data governance, let’s assume that a team of employees is working on a special project, and they need access to a specific set of data that they don’t typically have access to. They submit a User Access Request Form. Every organization has one. Your organization has one too.
The User Access Request Form typically kicks off a process that looks something like the diagram in Figure 5 (below). The Security team receives the request. The Security team may need to validate the contents of the target data set with the Data Team; the Security team may also need to escalate the request to the employee’s manager or executive sponsor of the team, and there may also be a secondary approval process. Once approved, the database and/or IAM permissions need to be updated to reflect the new permissions.
The biggest problem with this process diagram is the “Stop” oval. During the process, data is being governed carefully and meticulously. But, even after IAM and database permissions have been provisioned, many bad things can happen. For example:
Without continuous monitoring of context and policy -- i.e., without operationalization -- the world of data governance becomes a massive collection of unenforced contracts. Even periodic access control audits and sensitive data audits leave data essentially ungoverned between audits.
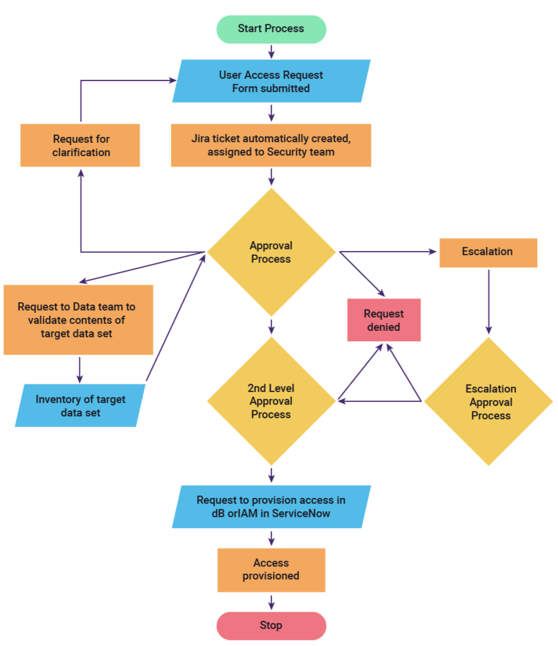
Figure 5: User Access Request Process
Data Governance Policies: More than Just Access Control
Many people -- and many commercial software solutions, for that matter -- might tend to oversimplify the role of Data Governance into managing access control, for example.:
Next-gen access control solutions might also include self-service portals for employees to request access, and obfuscated access, where employees can access data, but specific fields are masked or tokenized on the fly.
Access control is a necessary bedrock of a good data governance program. At the same time, access control is insufficient for good data governance.
Let’s explore some other types of Data Governance policies that enterprises have, and how those policies can often end up as well-intended pieces of paper on someone’s desk that aren’t actually enforced -- i.e., they never get operationalized.
|
Examples of Data Governance Policies |
Data Governance Broken Promises |
|---|---|
|
Data Preservation Policies |
|
|
|
|
|
|
|
|
|
|
Data Security Policies |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Compliance & Privacy Policies |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Data Management Policies |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Data Governance Needs to be Operationalized with DataGovOps
SalesOps measures and evaluates sales data to determine the effectiveness of a product, sales process, or campaign. Similarly, MarketingOps measures and evaluates marketing data to determine the effectiveness of marketing programs and campaigns.
DevOps is the combination of philosophies, practices, and tools that increases an organization's ability to deliver applications and services at high velocity.
DevSecOps automates the integration of security at every phase of the software development lifecycle, from initial design through integration, testing, deployment, and software delivery.
By analogy, Data Governance Operations -- or DataGovOps -- is the combination of practices and tools that:
DataGovOps is the collaborative data management practice focused on improving the communication, integration and automation of context and policy among all Data Governance stakeholders in an organization, including Security, Compliance, Privacy, and Data Owners. DataGovOps automates the integration of security and compliance at every phase of the data lifecycle. It’s the much-needed engineering counterpart to traditional Data Governance.
The cloud has transformed both the volume of data kept in organizations and the speed at which that data is growing. Given cloud scale and cloud velocity, Data Governance can no longer be a hodge-podge of manual steps, occasional audits, and a series of broken promises. It’s imperative for enterprises to automate and scale their Data Governance functions and invest in systems that continuously ensure that their data is being appropriately inventoried, stored, used, and deleted.
Now is the time to fix the broken promises of data governance. Now is the time for DataGovOps.






