
Protecting Data with Intelligent Query Inspection
Read Our Post



There’s an old adage in security: “You can’t protect what you can’t see.” This definitely applies to data security: you can’t protect your company’s sensitive data if you don’t know where it is. Your employees and vendors have more access to your data than ever before in the cloud, and they are moving it to new places, sharing it with teams, altering it, and taking it out of context way faster than security teams can possibly review — all of which puts sensitive data at risk. Forty-eight percent of employees have access to more data than they need to perform their job. Worse: “12% of businesses report their employees have access to all company data.” Knowing where your sensitive data is and how it is being used is a basic requirement for both regulatory compliance and data security.
Thesis:
Data classification means correctly identifying data according to its type, sensitivity, and value to the company. Getting data classification right is fundamental for businesses to be able to protect sensitive data and remain compliant while democratizing data among employees and partners. Classifying data may seem straightforward, but be sure to avoid common data classification pitfalls: treating classification purely as a technology problem, not continuously discovering and classifying data, and not collaborating across teams to make sure classification works seamlessly with security and compliance.
Data classification matters because it’s essential for compliance and preventing costly data breaches while also making the right data accessible to the people within your organization who need it.
Ninety-eight percent of companies surveyed in a June 2021 report experienced a cloud data breach in the past 18 months versus 79% last year; 67% reported three or more incidents. A 2021 IBM report found that today’s data breaches cost surveyed companies an average $4.24 million per incident. This marks the highest cost in the report’s 17-year history.
The core question is: What would happen if your company’s data was lost, altered, stolen, or destroyed? Do you store data types that are protected by law? Or proprietary data of crucial value to your organization? If the answer is yes — even if it’s just user emails — you need coherent data classification. As you classify the types of data you store, you’ll be able to accurately determine the level of security required and give your organization’s data policy purpose and structure.
Determining classification levels is just the beginning. Continuously finding and properly categorizing and protecting your data throughout its lifecycle is the real challenge.
Follow these six straightforward steps to create a company-wide data classification system that works.
1. Determine your data classification levels
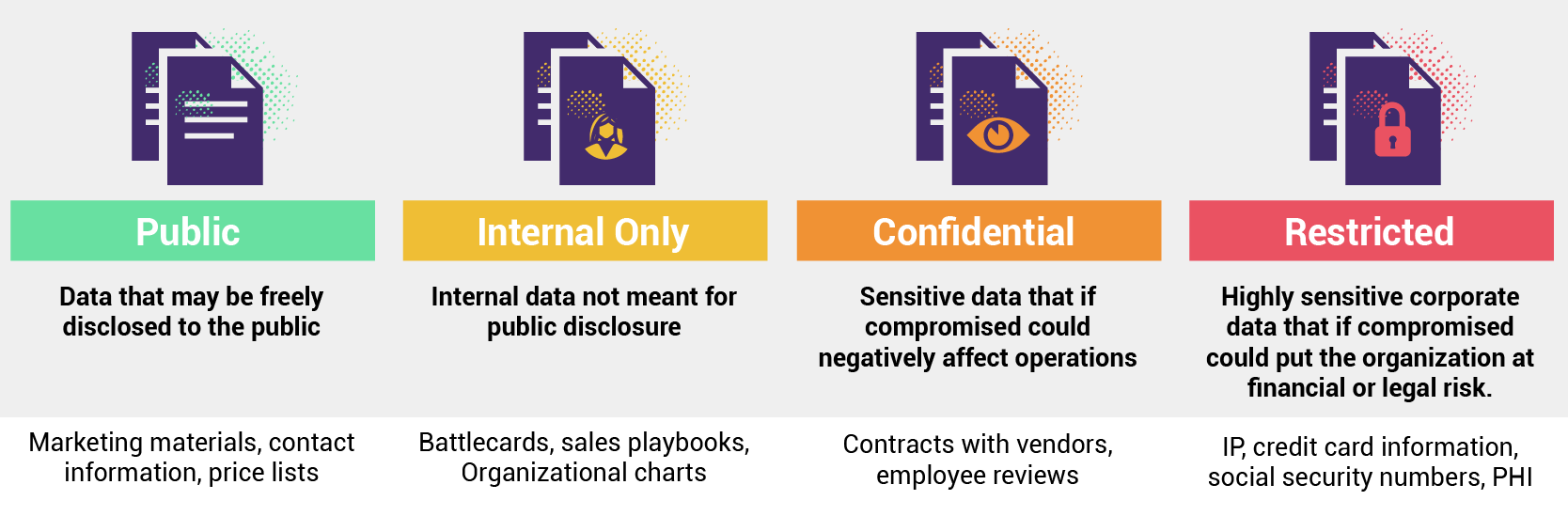 Keep data classification simple and useful for your employees. Aim for three or four levels of data classification appropriate to your industry:
Keep data classification simple and useful for your employees. Aim for three or four levels of data classification appropriate to your industry:
Begin by working with your legal team to interview department heads and get an in-depth understanding of your regulatory and contractual privacy and confidentiality data obligations. Understanding your legal obligations will help you create policies and adopt practices relevant to the types of data you steward.
3. Create a data classification policy
Make a simple classification system that addresses your data needs, and then create a company-wide classification policy that organizes your employees’ access to limit exposure. Start with a policy of least privilege — giving users only the minimum access needed to do their jobs. This will help prevent secure data from sprawling into stores where it’s not needed and where it’s at risk.
4. Map and track your company's data
Next-generation data discovery tools can build a detailed understanding of how data is moving through your stores and processes. This process requires automation. The current data ecosystem is fast-moving, and it is no longer possible to provide a timely and coherent response to audits or Data Subject Access Requests (DSARs) without automated data discovery and classification. Best-in-class data discovery tools employ a combination of automated classification and system suggestions that are approved or edited by users, so the AI becomes tuned to your company’s specific data classes and use cases over time.
Mapping where data is moving from/to is important, because data is often vulnerable when being accessed externally. Companies allow an average of 89 vendors to access their networks every week, and vendor-related breaches have been some of the costliest breaches in history. The 2017 Equifax breach was the result of a vulnerability in Apache Struts, a tool Equifax used to manage its online dispute portal. The total cost of the breach was about $1.38 billion, according to the settlement documents.
5. Put policy into practice
You’ve mapped your data and have rules around how the different classification levels must be treated. Now, work with engineering to build systems to enforce those guidelines.
6. Train and maintain
The 2019 Microsoft customer support data breach shows the importance of security training. “At the beginning of December 2019, Microsoft deployed a new version of Azure security rules. Microsoft employees misconfigured those rules and caused the accidental leak,” exposing 250 million entries including emails and IP addresses. Users need training specific to their level of interaction with data, but they also need intelligent tools that support them in this complex and rapidly changing field.
Next-generation data discovery tools constantly monitor and maintain classifications while data is at rest and whenever it is copied or moved. With these resources in place, restricted data is automatically tracked wherever it goes in your data stores and automatically classified and protected according to your policies.
Getting your data classification system up and running is a huge step. But data classification isn’t a system you can set and forget; it is best understood as a combination of technologies and processes that requires ongoing collaboration across teams. Once you’ve laid a foundation, take a realistic view of the challenges ahead and adopt a culture of proactive privacy to avoid these three common pitfalls.
Treating classification as just a technology problem
If your approach to data classification relies solely on technological considerations, then you are going to have blind spots in your system. No classification system works accurately on 100% of data, all the time.
“Don’t make the mistake of trusting your security technology unequivocally. Be technically prepared and diligent, but know that it will fail and be prepared to protect the brand and maintain customer trust. So start with the assumption that a motivated party will get access to your data. Now what do you do? Updates. Change in operational processes. Minimizing footprint and signature. Never let your guard down, updates, patches, research. Partner and collaborate,” says Dr. Scott Nelson, CTO and Executive Vice President at Logic PD.
Effective data classification starts with leadership and proceeds with human processes and technologies working in concert. Data classification needs to be seen as a combination of technologies and human supervision for it to be successful.
Not having continuous data classification
Data classification fails when it gets neglected, or when it’s treated as a periodic exercise that is done once a quarter for a compliance audit.
Correctly categorizing and securing data is urgent and ongoing, and it is a continuous responsibility for any organization that stores data. The good news is that once you have a policy, technology, and training in place, your data classification can become part of how you always do business. An automated data classification technology and process will not only save you money and time, but it will also make your data more secure and more compliant and open up new avenues for your data team to learn from the data you store.
Treating data classification as a stand-alone silo
Data classification fails when it is treated as a stand-alone function -- i.e., a job for only the Data Team to worry about. It takes a village to protect sensitive data, and the Data Team needs to work hand-in-hand with the Compliance and Security teams.
When it comes to Compliance, regulations are always changing and new regulations are always introduced. What data is classified as sensitive/not sensitive, and levels of sensitivity may change as well. Any lag between changing regulations and data classification may easily result in data and data usage falling out of compliance.
Data Teams also need to work closely with Security Teams. When data is classified as sensitive, the Security Team needs to know as soon as possible. Any lag can result in under-protected sensitive data and may result in data breaches. Security also needs to know as soon as possible if data is no longer sensitive, to decrease the number of false-positive alerts. Not only should the Security team be notified immediately whenever data is classified as sensitive -- ideally, the data security solution in place can automatically protect data as soon as it’s classified as sensitive.
Successful data classification is a team sport, and it’s a long game. Doing it right involves leadership, collaboration across departments, and next-generation automation combined with human supervision.
When those elements are in place, modern data classification provides a strategic advantage for your company. Gartner predicts that “through 2025, 80% of organizations seeking to scale digital business will fail because they do not take a modern approach to data and analytics governance” and that by 2023, organizations that have coherent classification systems and stewardship processes will have better cross-enterprise data sharing and, as a result, will outperform those that don’t. Making data classification technologies and processes part of how you do business now will improve your partnerships, help protect you from breaches and costly fines, and position your company for a future that is data-driven.
Ready for comprehensive, next-generation data classification that improves automation and collaboration? We’re here to help.






