
Protecting Data with Intelligent Query Inspection
Read Our Post



In today’s enterprises, data warehouses are business-critical tools for analysis and decision making tools. But how did we get here? Where did data warehouses actually come from? Igor Urisman, senior software engineer at Dasera, walks you through the fascinating evolution of data warehouses.
A data warehouse is just a specialized database, and the initial ideas around data warehousing were developed within the broader field of database management systems (DBMS). Between 1960 and 1975 the price of megabyte of disk storage fell from $5,000 to just over $100 while advances in media density permitted reduction of the drive size to a point where a lot of data could be stored by an average computer system.
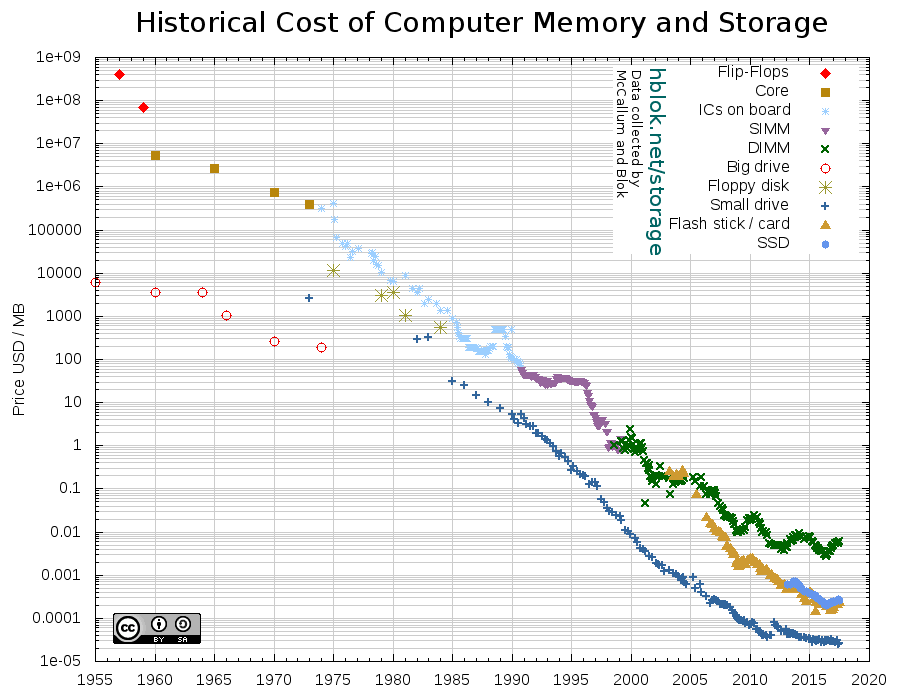
As capacity grew, companies began to collect and keep more information on disk, instead of dumping historical data on tape. Tape access was slow and required a human operator, so access to historical data was limited to such jobs as month-end processing, which took hours of computer and human labor. But with all that historical data accessible directly, the field of business reporting was born: business reports were no longer human-dependent.
The only wrinkle in that success story was that reports could only be run at night. During the day, reports ran the risk of producing inconsistent summaries and required extra hardware capacity to avoid interfering with user transactions. To mitigate this risk, business reports ran in a nightly batch.
To help technical and non-technical users write business reports faster than in a general-purpose programming language -- like COBOL or Fortran -- several new commercial languages were developed, like Easytrieve (Pansophic, 1970) and Natural (Software AG, 1979).
 (What report-writing software looked like in 1970)
(What report-writing software looked like in 1970)Had the price of disk storage and compute power not continued to decline, we’d still be depending on the nightly batch to glean any business intelligence from operational data. But they did continue to drop: by 1985 the price of a megabyte of disk storage was around $20, and a megabyte of RAM memory was only 10 times as much.
This continued decrease in storage and memory cost allowed software programs to rapidly increase in the volume of disk space and the amount of operating memory used, giving rise to Database Management Systems (DBMS), the new paradigmatic software category of the 80s and the 90s. Most of the databases started at that era are still around today e.g. Oracle, DB/2, Postgres, SQL Server.

The biggest advance offered by these relational databases was SQL, the data access language first proposed by E.F. Codd in 1970. What was incisive about SQL was that it provided a powerful abstraction over the physical data organization on disk from the logical data organization in the mind of an application programmer. With SQL, the application programmer could treat data access as declarative. Getting the data he needed was a matter of expressing what he needed, rather than how to get it from disk. The success of SQL was so resounding that it remains the principal language of data warehouses to this day.

This separation between physical and logical data organizations permitted tailoring of a DBMS to a particular access pattern, while keeping the application layer general. Two principal access patterns were identified: online transaction processing (OLTP) and online analytical processing (OLAP), which remain relevant to this day.
The OLTP access pattern is typical of operational databases, which run a large volume of narrow transactions operating on a handful of rows. The data consistency and durability guarantees are critical for the operational databases, leading to highly normalized schemas and extensive indexing. In addition, operational databases frequently make use of procedural extensions.
Conversely, the OLAP access pattern is typical of business reports and various GUI analytical tools, which query a few columns summarized over a large number of rows. This access pattern frequently assumes few to no updates, never uses procedural extensions and typically cannot take advantage of indices.
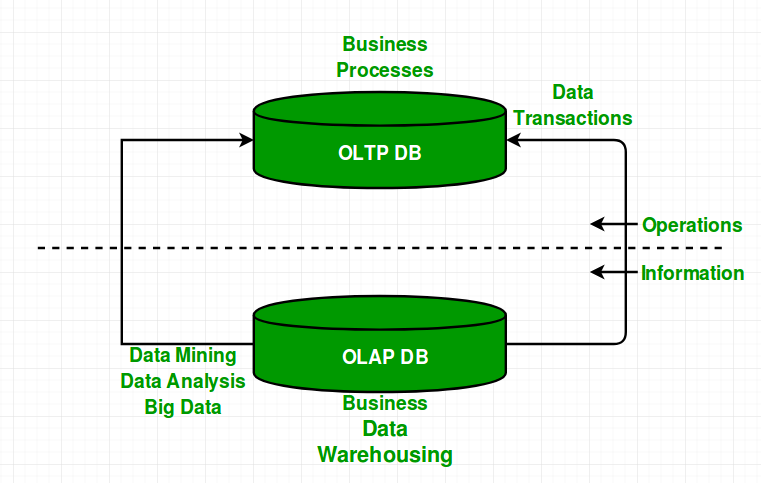
This dichotomy between OLTP and OLAP is at the heart of data warehousing. In fact, a data warehouse is little more than a copy of the operational database, with its data reorganized with the goal of supporting analytical queries. The predominant method of organizing warehouse data is the star schema, which reimagines business datasets as multidimensional tables. For example, a college campus warehouse may track various facts like grades, courses taken, etc, as points in a three-dimensional space of time, students, and courses. The resulting schema will have the fact table in the middle with foreign keys referencing three dimension tables, forming a 3-pointed star around the fact table.
Although not the only approach to organizing a data warehouse, the star schema has proven very effective in a wide range of business applications and continues to be the predominant data warehouse structure to this day.
The next big advance in data warehousing came as the result of virtualization of computing. The shift to the cloud removed human-related limitations from the task of warehouse administration in the form of managed database solutions, like Amazon Redshift. Combined with further technological advances in storage, memory and massively parallel processing, companies now can efficiently run analytical queries against petabytes of data.

Furthermore, the most recent advances in cloud native data warehousing technologies, like Snowflake and Amazon Redshift Spectrum, can seamlessly combine traditional block storage with the effectively unbounded object storage, expanding the potential warehouse size to exabytes.
Today, the average size of a modern data warehouse is pushing 100 terabytes — enough to contain all warehouses on the planet in 1990. (The first 1 terabyte data warehouse was achieved in 1991 by Wal-mart.) These troves of data contain great business intelligence no money can buy on the open market: real customer behavior, experimentation data, machine learning training sets, etc. It is this intelligence, locked in the vast sea of raw data, that prompted Clive Humby, the British mathematician and the brain behind Tesco’s club card, to call data “the new oil” — companies stand to realize significant monetary value from this raw data, if they can find a way to economically refine it into usable insights.

It turns out, however, that the new-oil metaphor has little going for it. To see why, the Wired columnist Antonio García Martínez offers this compelling thought experiment: imagine the Amazon van drops off at your doorstep not a box with shoes, but a box full of disk drives. Even though this data is worth billions to Amazon, your ability to monetize it is nil, according to García Martínez.
However, to agree with the argument that monetizing a tanker full of crude is qualitatively easier than monetizing Amazon’s customer data is to ignore the thousands of data breaches perpetrated annually with the goal of stealing customers’ personal information. Turning this data into cash is a fairly straightforward exercise for someone familiar with the ways of the Dark Web.
Data warehouses are particularly vulnerable to data breaches because they contain massive amounts of sensitive data and access control measures -- typically employed to safeguard operational databases -- are hard to apply to data warehouses. A large number of users must access the warehouse to take advantage of the data.
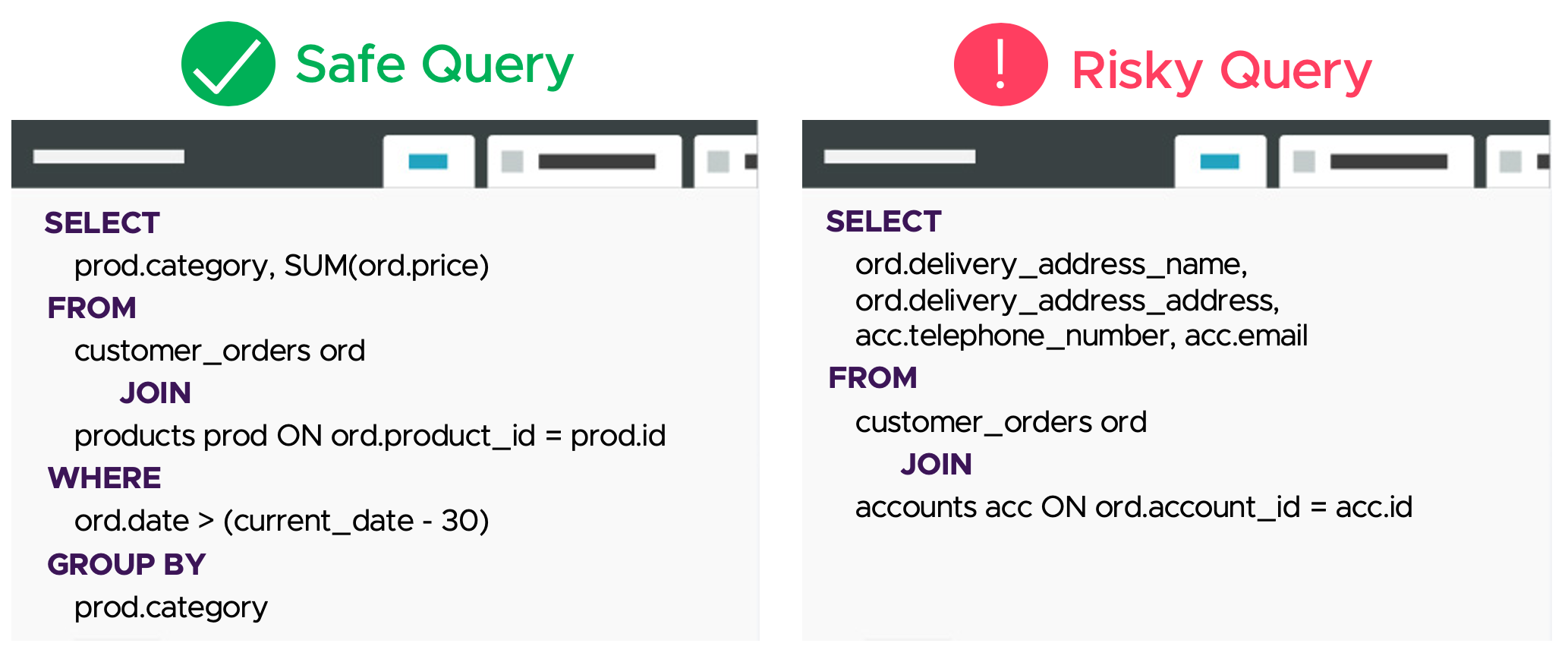
The demand for illicitly acquired personal data is great and growing, as ways to monetize it are developing. Thus, the more apt metaphor for data is not oil but rosewood — the most trafficked natural resource on the planet.
Frequently, the trafficking of personal data starts not with an external intruder, but with an insider. As many as five thousand insider breaches are projected to take place in 2020. While most of them will not be committed with criminal intent, the cost they will collectively exact on breached companies is a whopping $57B.
Defending against insider breaches is a hard problem because, for the most part, it is a behavioral problem. If everyone did the right thing, nothing bad would ever happen. But people are inherently fallible and (mostly) through negligence, or (occasionally) maliciously, they write bad queries that expose personal information. Dasera has developed novel technology to spot these access anomalies in real time and alert administrators, enabling them to take corrective action, minimize 'time to detect and remediate', and ultimately reduce the cost of insider threat.
-----------
To follow the Dasera engineering blog, enter your email below.






